Big Tech Companies’ AI Competitiveness Strategies (Google, MS, OpenAI, Anthropic, X)

As Artificial Intelligence (AI) technology deeply permeates our daily lives and businesses, the landscape of the global tech industry is rapidly shifting from a mere competition in algorithm development to a massive physical barrier struggle to monopolize capital and infrastructure. While it may seem complex due to grand technical jargon, its essence surprisingly aligns perfectly with the common-sense logic of ‘product development costs and real-time distribution margins’.
Through this article, readers will take away exactly three core insights today:
The fundamental cost disparity between training (one-time secret recipe development) and inference (real-time infinite serving)
The moat of in-house semiconductor (ASIC) design to break free from the high-margin dominance of a monopolistic supply chain (Nvidia)
The real profit-generating entry barriers built by the global five giants (Google, MS, OpenAI, Anthropic, xAI) in their respective domains
[Onboarding] The Common-Sense Differentiation of AI Infrastructure’s Two Pillars: ‘Training’ and ‘Inference’
The first step to understanding AI infrastructure is to grasp the clear distinction between ‘Training’ and ‘Inference,’ the two pillars governing the machine learning lifecycle.
‘Training’ is the process of developing a ‘special cooking recipe’ that is unique in the world. To achieve the best taste, vast ingredients (data) are gathered, and the optimal cooking method is found by simmering (computation) hundreds of times over days and nights in front of a cauldron. The initial recipe development phase incurs substantial fixed costs. However, once the recipe is complete, the gas can be turned off. This is the ‘training’ phase of creating an AI model for the first time, and financially, it corresponds to a massive, one-time ‘Capital Expenditure (CapEx)’.
‘Inference’ is the daily routine of using that completed secret recipe to prepare and serve dishes to customers whenever they order. While not as difficult as recipe development, if millions of customers arrive, ingredient costs and gas expenses (inference costs) continuously accumulate in real-time every time a dish is cooked. This is the ‘inference’ phase where users ask AI questions and receive answers, and it represents ‘Variable Operating Expenses (OpEx)’ incurred throughout business operations.

In the past, all attention was focused solely on creating ‘superior secret recipes (training).’ However, with the popularization of AI services today, the daily accumulated inference computation costs now account for 80% to 90% of the total AI lifecycle costs. In other words, the real battle has completely shifted its paradigm from a ‘cooking performance leaderboard’ to a cost-reduction fight over ‘who can serve tens of millions of dishes per second, even a single won cheaper and faster’.
This is the core of ‘inference economics’ that big tech companies are staking their lives on.
1. Google: The Power of Custom Silicon Independence and YouTube’s Exclusive Raw Material Farm
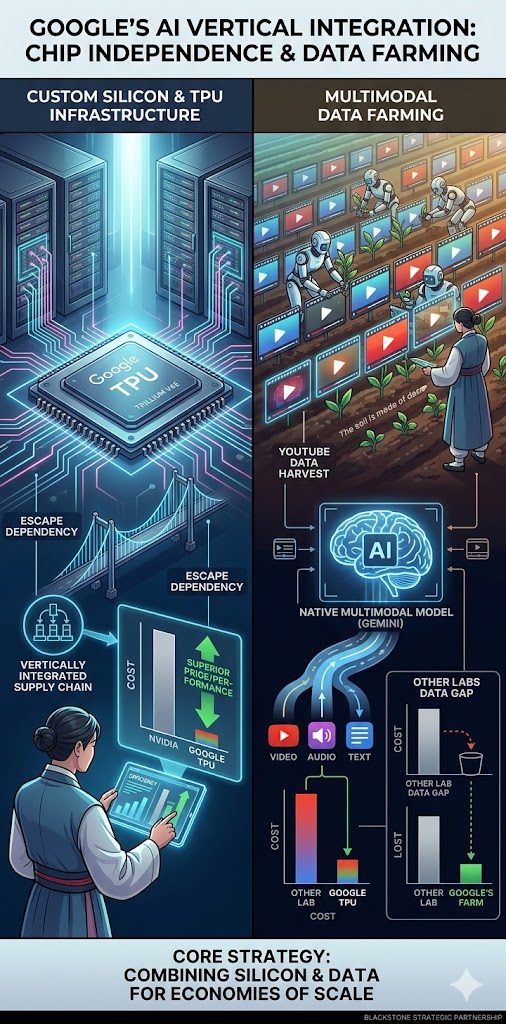
Google, metaphorically speaking, is the sole giant that has perfectly vertically integrated its entire supply chain, from the farm harvesting ingredients (data) to secret recipe development (Gemini model) and the special pot for cooking (in-house semiconductor TPU).
While competitors are burdened by financial strain due to their dependence on Nvidia’s monopolistic dominance and high chipset margin structure (Nvidia Tax), Google has achieved complete infrastructure independence based on its self-developed AI accelerator ecosystem, the TPU (Tensor Processing Unit).
Google’s latest 6th-generation accelerator, Trillium (TPU v6e), demonstrated high-density scaling efficiency of up to 99% in distributed computing, proving superior cost-effectiveness compared to Nvidia chipsets. Furthermore, by launching a strategic joint venture (JV) with asset manager Blackstone, Google skillfully distributed the burden of large-scale capital expenditure to financial capital while simultaneously securing a 500MW-class mega server complex to deploy its TPUs.
Google also monopolizes an irreplaceable raw material farm: YouTube, the world’s largest video platform. While other frontier research labs face data depletion due to text resource shortages and copyright infringement disputes, Google refines YouTube’s video sources to cultivate Gemini as a ‘native multimodal’ genius, capable of simultaneously combining and understanding sight and sound from birth, thereby forming a formidable physical barrier.
[Key Insight]
Google has secured the most complete independent path in the cost competition of inference economics by combining its specialized accelerator chip (TPU) with its exclusive multimedia asset, YouTube. Check Google’s 6th-gen TPU detailed information
2. Microsoft (MS): Enterprise Governance Dominance and the Moat of Strictly Enclosed Partnerships
Microsoft is simultaneously researching frontier model intelligence independently and leveraging an exclusive partnership grid that locks OpenAI, the global center of generative AI power, into the Azure ecosystem as its core weapon.
The mutual binding agreement between the two companies is extremely thorough. OpenAI’s API computations are exclusively served only within the Azure cloud environment, and even if OpenAI generates commercial revenue through other infrastructure partnerships, a significant portion of that share is reverse-allocated to Microsoft’s revenue, a net meticulously woven.
Furthermore, Microsoft’s true strength lies in its exclusive lock-in within enterprise serving environments. It has established the ‘Microsoft Foundry’ security sandbox virtualization network, a platform designed to allow financial and public enterprises, for whom security is paramount, to securely operate large-scale agents, thereby dominating the governance of the Azure virtualization layer.
Concurrently, Microsoft is deploying its 2nd-generation in-house inference chip, ‘Maia 200,’ which adopts TSMC’s 3nm cutting-edge process, significantly reducing serving costs (Tokens per dollar) and diversifying its supply chain.
[Key Insight]
MS has secured cutting-edge intelligence through an exclusive licensing agreement with OpenAI and preempted dominance in the enterprise AI operation market through the ‘Microsoft Foundry’ security control network. Check MS Azure AI Virtual Governance
3. OpenAI: Capital-Efficient Lease-Based Pivot and the Gigawatt Grid ‘Stargate’
OpenAI chose a dramatic strategic bypass to defend against the astronomical capital expenditure (CapEx) pressure and financial losses associated with building its own kitchens (data centers). Instead of a direct ownership roadmap, it pivoted to a ‘global lease-based multi-cloud architecture’ that distributes asset liabilities to partner cloud infrastructure companies.
The core of OpenAI’s diversification strategy is a colossal $300 billion computing serving deal with cloud company Oracle. This clever arrangement allows OpenAI to lease and utilize 4.5 GW of accelerated computing power annually, with Oracle undertaking the financial risk of raising massive debt to purchase and build state-of-the-art accelerator servers.
On this Stargate distributed multi-cloud grid, OpenAI is continuously releasing its ‘GPT-5’ family models in very granular sub-stages (e.g., GPT-5, 5.2, 5.5), seizing leadership in intelligence and computational efficiency by not giving competitors time to establish engineering standards.
[Key Insight]
OpenAI is leveraging infrastructure capital from Oracle and others to distribute financial burdens and is maintaining leadership in frontier intelligence by operating a granular model release roadmap. OpenAI & Oracle Partnership Detailed Report
4. Anthropic: Platform-Independent Diversification and the ‘Constitution Imprinted with Conscience’
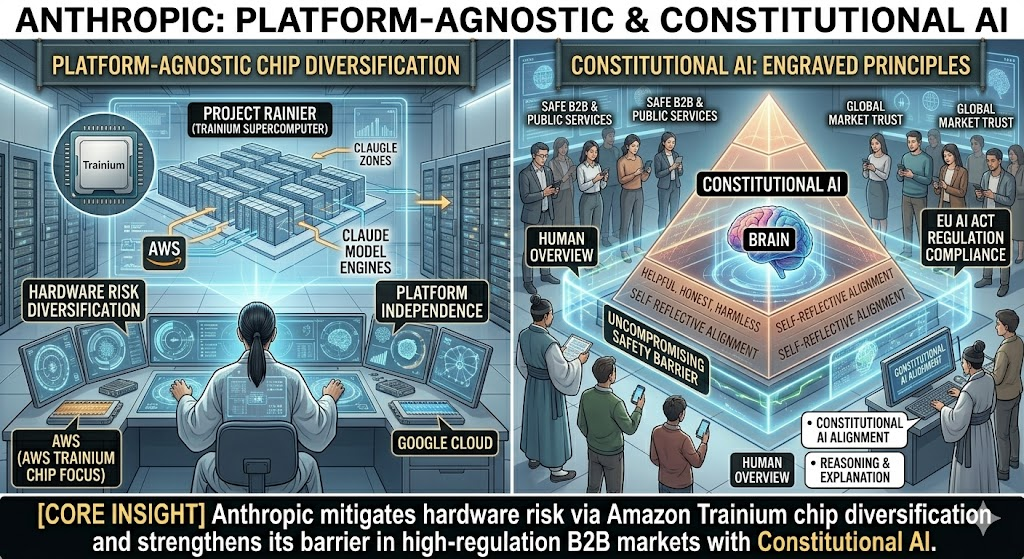
Anthropic adheres to a strategy of ‘platform-independent diversification’ to proactively defend against the risk of being locked into hardware due to dependence on a specific cloud big tech. They are focusing on securing computational resources by using Amazon (AWS) and Google Cloud as their two main pillars.
Through a deepened partnership with Amazon, they are specifically operating ‘Project Rainier,’ a single, massive supercomputer complex designed long-term based on Amazon’s accelerator chipset, Trainium, which is being used as the next-generation training and large-scale global serving engine for the Claude model.
In addition, the unique trust barrier Anthropic has built is its ‘Constitutional AI’ alignment technology. Beyond merely teaching models to obey commands, they have standardized a ‘principle-based alignment technology’ that enables models to derive correct behavior and explain their reasoning based on constitutional value principles.
This constitutional alignment technology prioritizes safety and human oversight as non-negotiable values, demonstrating overwhelmingly perfect defense capabilities in adversarial bypass threat tests compared to other companies. Thanks to this, it has emerged as an irreplaceable core trusted platform for enterprise customers in highly regulated markets such as the European Union (EU AI Act) and global financial and public sectors.
[Key Insight]
Anthropic has diversified hardware risk through Amazon’s Trainium chip and has solidified barriers in the high-risk, highly-regulated B2B market through its unique trust mechanism, ‘Constitutional AI’. Anthropic Constitutional AI Standard Constitution Original Text
5. X (xAI): The World’s Strongest Acceleration Complex ‘Colossus’ and the Wildness of Real-time Social Raw Materials
xAI, led by Elon Musk, demonstrates an extremely wild competitiveness of ‘single cluster physical integration at extreme speed and omnidirectional data extraction’ instead of sophisticated bypass strategies. In 2026, they merged with aerospace company SpaceX, integrating satellite communication backbone technology with a gigawatt computing grid.
The symbol of xAI’s infrastructure is the ‘Colossus’ supercomputer complex in Memphis, Tennessee. Following Colossus 1, which was brought online in just 122 days from groundbreaking with liquid cooling solutions, they recently fully activated ‘Colossus 2,’ the world’s first single-grid computer with power consumption exceeding 1GW among single data centers, proving their physical execution capability to dominate a total 1.5GW single grid.
Their data weapon is the real-time full data scraping rights of the X (formerly Twitter) platform. While other search crawlers struggle with outdated web texts, hampered by traffic limits and robot exclusion protocols (robots.txt), xAI directly injects real-time social posts and news feeds generated globally every second into its neural networks.
Furthermore, the integration of Tesla’s road driving vision data and the Optimus humanoid project is securing an overwhelming virtual-physical data combination moat that directly learns the physical laws of the real world.
[Key Insight]
xAI has secured a launchpad for physical intelligence by combining the overwhelming operational power of a 1.5GW-class single acceleration cluster (Colossus) with live data from the X platform and Tesla’s physical autonomous driving data. xAI Colossus Operational Status Analysis
Next Step
The AI acceleration war waged by global big tech companies ultimately converges and condenses into the following three physical competitive advantages:
The establishment of an ASIC (in-house accelerator chip) ecosystem to avoid the high margins of monopolistic suppliers
Dominance over single gigawatt (GW)-class power grids and cooling infrastructure, which dictate the speed of intelligence training and serving
Virtualization sandboxes to prevent corporate data leakage and trust lock-in barriers through ethical constitutions
Practical Guide for Readers (Next Steps) – 3 points:
Metrics to check: During each big tech company’s quarterly earnings announcements, check the trend of Capital Expenditure (CapEx) growth and how the serving proportion of their in-house accelerator chips (TPU, Maia, Trainium) is expanding. This is the fundamental source for protecting cost margins.
Actions to take: As AI computational demands increase exponentially, the power supply chain will become a bottleneck limiting the scale of intelligence. Monitor the performance improvement trends of power transmission and distribution grid infrastructure and key liquid cooling component companies that support mega-acceleration complexes.
Key keywords to search: When big tech companies release their earnings guidance, meticulously analyze the trends of ‘Inference Cost and Tokens per Dollar.’ The company that dramatically lowers serving costs, as much as performance, will ultimately monopolize the profits.